
Key Takeaways
- The right execution platform should fit the real workflow, not only the agent demo.
- Environment control matters because state, retries, and human takeover shape real outcomes.
- Browser and mobile lanes should be chosen by task boundary, not by habit.
- A small pilot is the fastest way to see whether the platform reduces cleanup.
How to choose an AI agent execution platform starts with one direct rule: choose the platform that can run your real tasks in a controlled environment with clear recovery and review rules. The choice is not only about reasoning quality. It is about whether the platform can execute, pause, rerun, and explain what happened.
That distinction matters because many teams already know an agent can produce a plan. The harder problem is turning that plan into repeatable work across browser sessions, mobile environments, and human checkpoints.
Primary sources help frame the decision. W3C WebDriver defines browser automation through explicit sessions and commands.1 Playwright separates browser state with contexts.2 Android Enterprise describes managed device environments for structured control.3 Those sources all support the same practical idea: reliable execution depends on controlled state.
Pre-Setup Requirements and Checks for an AI Agent Execution Platform
Do not begin with a vendor feature grid. Begin with the task and the runtime.
Write down:
- which tasks stay in the browser
- which tasks require mobile execution
- where a person must review or approve
- how the workflow should resume after interruption
This is also the point where many teams move from a simple AI browser discussion into mobile automation, cloud phone, and device isolation evaluation.
The Core Workflow for How to Choose an AI Agent Execution Platform
Use a short selection sequence:
- Pick one repeated workflow, not the whole operation.
- Split the workflow into browser, mobile, and review steps.
- Check whether the platform can reopen the same state after interruption.
- Check whether the platform logs outcome classes clearly.
- Check whether human takeover happens at the correct point.
This sequence is more useful than comparing agent demos in isolation. A polished reasoning layer is not enough if the runtime and recovery model stay weak.
How to Check Environment Control in an AI Agent Execution Platform
Environment control decides whether the same task can run again without confusion. If the platform cannot reopen the same state, route the same account, or pause at the same step, the system will create manual rescue work.
Review these areas:
- browser session isolation
- mobile device separation
- account routing clarity
- reviewer handoff points
- rerun rules after interruption
For browser work, Playwright contexts are useful because they show why state boundaries matter in repeated execution.2 For mobile work, Android Enterprise is useful because it frames device management as a controlled workspace problem instead of a loose automation script.3
How to Verify the Setup Is Working in an AI Agent Execution Platform
Verification should focus on repeatability, not first-run success.
Use these checks:
| Check | Why it matters | Pass sign |
|---|---|---|
| State reopening | Shows whether reruns are manageable | Same lane resumes cleanly |
| Review control | Keeps approvals explicit | Visible pause points |
| Logging | Reduces hidden cleanup | Clear run status |
| Runtime fit | Prevents mismatch between task and environment | Few manual workarounds |
AWS Device Farm and BrowserStack App Automate both emphasize reproducible mobile environments for repeated work.4 5 The same discipline applies to a broader execution platform.
How to Compare AI Agent Execution Platform Options During a Pilot
Do not compare platforms on vendor language alone. Compare them on one workflow that matters and one scorecard the team can read.
Use a pilot with:
- one workflow that already repeats each week
- one browser lane and one mobile lane if both are required
- one reviewer who approves or stops the run
- one log format for success, retry, blocked, and manual takeover
- one recovery test after a forced interruption
The point is not to find the perfect platform in one pass. The point is to identify whether the execution layer removes cleanup or simply hides it.
Where Teams Usually Get Stuck
Most teams get stuck in one of four places:
- they test the happy path only
- they use one loose runtime for unrelated tasks
- they skip human review design
- they cannot tell whether the failure came from reasoning or execution
Those problems are not minor details. They are signs that the platform is not yet ready for production-like workflows.
Another common issue is ownership drift. One team may choose the platform, while another team has to review outputs, repair failures, and maintain account state. If those groups do not agree on stop rules and recovery rules, the pilot will produce confusing results.
This is why the platform decision should include the people who will operate the workflow after launch. A clean demo from an isolated test owner does not prove that the platform fits a shared operational process.
Next Steps After the First Pass with an AI Agent Execution Platform
After the first platform check, use a small rollout instead of a full migration.
- Pick one pilot workflow. Use a task that already repeats.
- Assign one owner. That person should review failures and retries.
- Track correction cost. Do not focus on volume alone.
- Compare browser and mobile lanes. Make sure each step stays in the right runtime.
- Expand only after stable reruns. Scale after recovery is predictable.
If the workflow depends heavily on account-based execution, review multi-account management before broader rollout. Environment design often determines whether the agent layer stays usable.
It also helps to document one rollback path before rollout. That path should explain when the team pauses the workflow, who approves a rerun, and how account state is checked before the next attempt. A platform is easier to trust when the rollback path is visible before the first failure happens.
Frequently Asked Questions
What matters most in an execution platform?
Environment control and recovery clarity matter most.
Is reasoning quality enough?
No. Strong reasoning still needs a controlled runtime.
Should every platform support mobile execution?
Only when the real workflow depends on mobile or app-native steps.
What should the first pilot include?
Use one repeated workflow with clear pass and failure states.
Why does logging matter so much?
Because poor logs make manual cleanup slower after failures.
What is an early warning sign?
Frequent reruns without clear root cause are a strong warning sign.
When should the team expand the rollout?
Expand after routing, review, and recovery stay stable in the pilot.
Conclusion
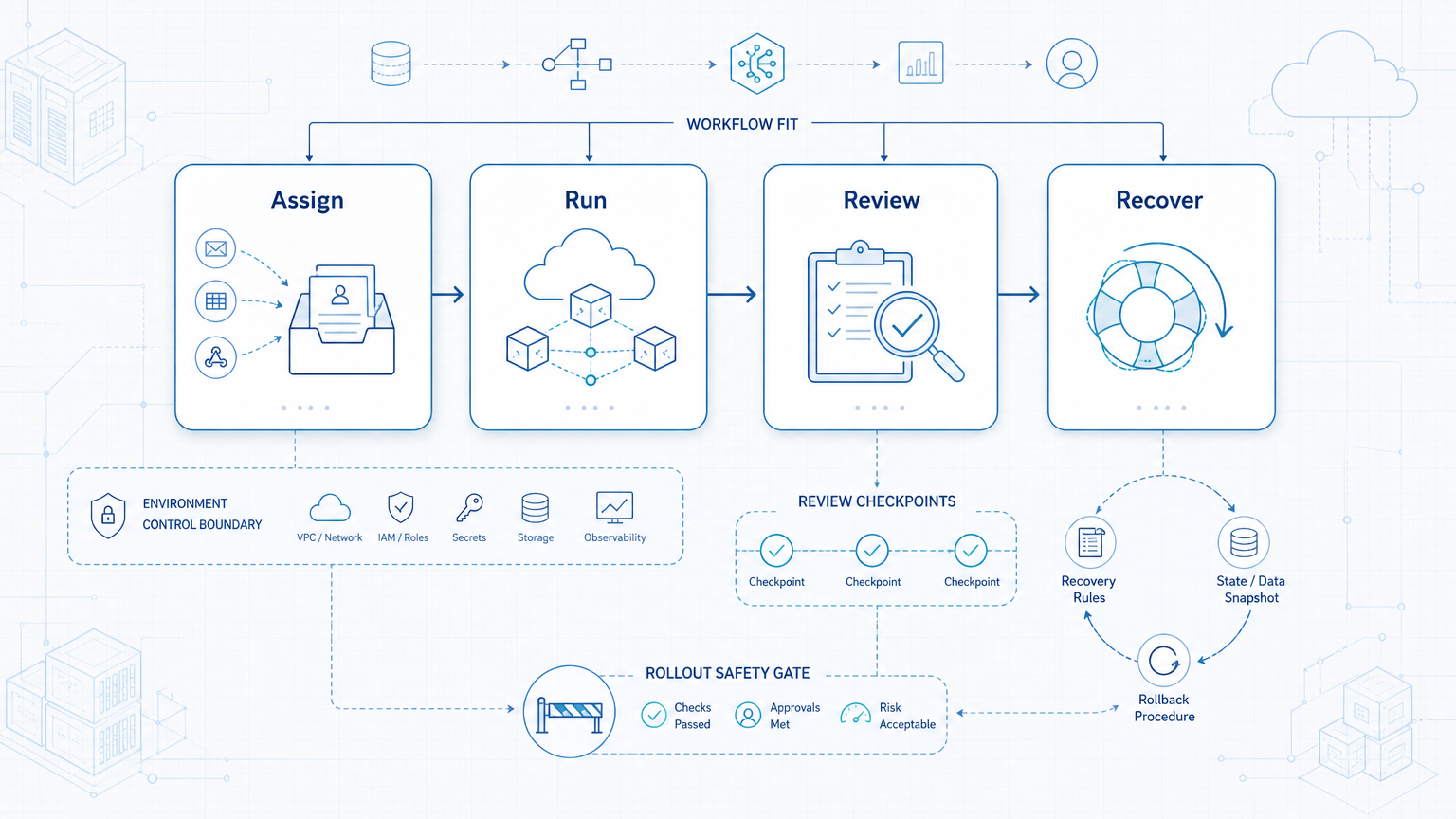
How to choose an AI agent execution platform comes down to a practical order: map the workflow, test the runtime, validate the rerun path, and then scale. The best platform is the one that keeps execution legible after normal interruptions.
Before deciding, confirm three things: the workflow fits the platform, the environment stays controlled, and the team can explain failures quickly. If those checks pass, the platform is much closer to real operational use.



