
An AI employee platform is execution infrastructure that lets software workers complete bounded growth tasks inside controlled browser, mobile, account, and review environments. The main question is not whether an AI can produce an answer. The harder question is whether the work can run in a real account context, leave proof, stop at the right boundary, and hand exceptions to a human. Keep it visible.
Real growth operations execution usually touches login state, device context, forms, uploads, dashboards, and external sites. Those surfaces are messier than a chat window. A practical platform needs browser sessions, mobile execution lanes, task policy, action logging, and recovery checks that stay tied to each run. Proof comes first.
MoiMobi treats the cloud phone layer as one part of execution infrastructure, not the whole product. Mobile lanes, browser lanes, device isolation, proxy routing, content preparation, and task review need to work together. That operating model matters when a team wants AI employees to do repeatable work rather than produce isolated suggestions. Name the owner.
Google's people-first content guidance is useful outside SEO too. A task system should make the work understandable for the person who reviews it. Technical browser standards such as W3C WebDriver and the Chrome DevTools Protocol also show why execution needs explicit sessions, targets, and observable actions. Stop early.
Key Takeaways
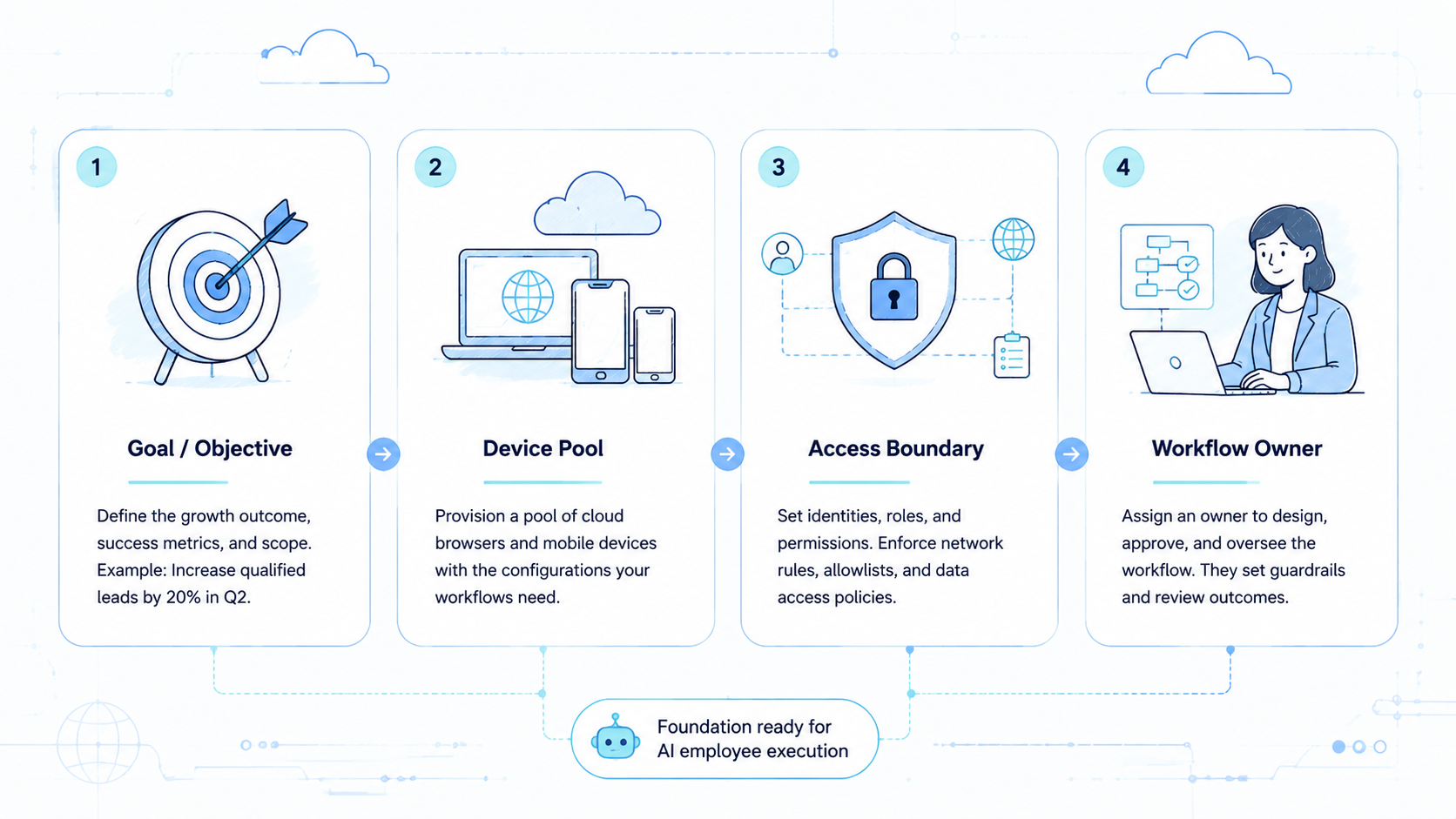
- An AI employee platform needs execution context, not just prompts and output text.
- Real growth operations work requires clear ownership across browser, mobile, account, and run state.
- Teams should start with narrow lanes where success, proof, and recovery are easy to inspect.
- Good platforms separate planning, execution, verification, and exception handling.
The Core Idea Behind an AI Employee Platform for Growth Execution
Useful AI work is not a general assistant with unlimited freedom. The worker operates inside a defined lane. The operating layer decides which environment the worker may use, what action types are allowed, what evidence must be stored, and when a human needs to review the result. Check the lane.
This distinction becomes visible when a workflow leaves a document editor. A worker may need to open a site, choose the correct account, load a prepared asset, fill a field, check a dashboard, or switch to a mobile app.
Each step changes the execution surface. The system must know which browser, device, account, and task run are active. Context wins.
Promoi's internal architecture documents describe the same principle as isolation across user, browser, and run dimensions. That maps cleanly to SEO and operations work. A team should not let two task runs share unclear memory, an old browser target, or a global current-account variable.
Run identity and environment identity need to travel with every action. Use fewer variables.
The decision rule is simple: if a task cannot be repeated, inspected, or recovered, the lane is not ready for an AI employee. It may still be a good one-off experiment. Do not sell it internally as operational automation. Record the reason.
Why Teams Search for Growth Operations
Teams usually search this topic after hitting the gap between AI output and work completion. A model can suggest a reply, summarize a page, or prepare a spreadsheet. The business result still requires execution inside an account, a tool, or a mobile app. Small checks matter.
Three problems usually drive the search:
- Context drift: the worker loses track of which account, browser, or device is assigned.
- Weak proof: the task appears complete, but no screenshot, state change, or log proves it.
- Recovery confusion: a failed action stops the batch, yet nobody knows whether to retry, skip, or escalate.
Structured execution reduces these issues by giving each run a traceable path. The run record should store the task input, selected environment, action route, evidence, and review state. Judgment still belongs to the team.
Organized facts make that judgment faster. Fix one rule.
For browser-heavy work, this is also why session and target handling matter. Browser automation standards expose actions through explicit sessions because the page, frame, and target can change. A production team needs similar discipline in its own workflow model. Context wins.
Where Real Work Happens: Browser, Mobile, and Account Context
Real growth tasks rarely stay inside one interface. A growth operator may prepare content in a content library, open a browser profile, verify account state, move an asset, and then check the result on a mobile surface. An execution platform has to treat those surfaces as connected but isolated. Route with care.
The browser lane is best for dashboards, web forms, account settings, research queues, and admin workflows. The mobile lane is best for app-only actions, mobile account checks, and device-specific work. The account lane holds ownership, permissions, and routing rules.
None of these lanes should pretend to be the others. Review the cause.
| Execution layer | What it controls | Failure signal |
|---|---|---|
| Browser session | Tabs, pages, web actions, and dashboard work | Wrong target, stale page, or missing login state |
| Mobile device lane | App execution, mobile identity, and device-side checks | App state mismatch or device context drift |
| Account workspace | Ownership, assets, credentials, and review state | Unclear operator handoff or mixed account evidence |
| Run record | Task input, action path, proof, and outcome | No reliable way to replay or inspect the run |
MoiMobi's device isolation, proxy network, and multi-account management pages are natural next checks for teams mapping those layers. The point is not to add complexity. The point is to prevent hidden shared state from becoming the reason an AI worker fails. Write the boundary.
How to Evaluate an AI Employee Platform for Growth Tasks
Start with one narrow task lane. A good pilot might be "check account inbox status and file exceptions" or "move prepared assets into a campaign dashboard." A poor pilot is "manage all growth work." Broad mandates hide failure causes.
Use these pass/fail checks before expanding:
- Environment binding: every run names the browser, mobile lane, or account workspace it can touch.
- Action boundary: the platform separates direct actions from observed actions that need page state.
- Evidence rule: each completed run stores proof that a reviewer can inspect.
- Stop condition: the worker knows when to wait, escalate, or end instead of improvising.
- Recovery path: failed runs return a reason, not just a generic error.
Action handling deserves special attention. Promoi's ActionExecutor guidance treats execution as a controlled layer rather than something delegated fully to the model. That is the right operating shape.
A model can choose a plan or propose a next step, but the execution engine should enforce allowed actions, target context, and policy. Keep scope narrow.
Operating Fields an AI Employee Platform Should Track
Execution quality improves when the platform stores the right fields before the worker starts. The worker should not discover ownership, account scope, or proof format halfway through the task. Those details need to be part of the run contract. Show the evidence.
The minimum field set is practical:
- Task intent: the short outcome the worker is trying to produce.
- Account scope: the account, group, or workspace assigned to the run.
- Execution surface: browser, mobile device lane, or both.
- Allowed actions: what the worker may do without approval.
- Proof format: screenshot, status value, saved link, or output text.
- Stop reason: the category to use when the worker cannot continue.
This field set also helps managers audit the workflow. A completed run can be checked against the intended account and proof rule. A stopped run can be grouped with similar failures.
Over time, the team can see whether failures come from missing inputs, stale sessions, weak instructions, or the wrong execution surface. Reduce guesswork.
Field discipline sounds basic, but it changes the daily operating rhythm. Teams stop asking, "What did the AI do?" They start asking, "Which lane failed, and which rule should we improve?"
That is a better question for scaling. Keep the question concrete.
Example Run Design for an AI Employee Platform
A simple example makes the control model easier to judge. Suppose a team wants a worker to check account status, collect a screenshot, and file anything unusual for review. The task sounds small, yet it still needs careful setup. Track the exception.
The run should begin with a task ID, account workspace, assigned browser profile, and proof requirement. The worker opens only the allowed dashboard, checks the named account, records the status, and stores proof in the run record. A normal result moves to review.
An unclear page state moves to stopped status with a reason. Make handoff clear.
The same pattern works for mobile work. A worker may open an assigned device lane, check an app state, and return a proof image. The key is that the mobile lane is not a vague device pool.
A named execution context ties the account to the task. Pause before scale.
This example also shows why broad prompts fail. "Check our accounts" is not an execution contract. "For account group A, check status field B in environment C, store proof D, and stop on condition E" is much closer to a usable growth lane. Test one lane.
Specific beats broad.
Teams can build from this shape. First define one status check. Then add one asset movement task.
Later, combine web and mobile steps only after each separate lane has a reliable proof and recovery record. Keep it visible.
One useful review question is blunt: can a new operator understand yesterday's failed run without asking the person who launched it? If the answer is no, the platform still lacks operational traceability.
Mistakes That Reduce Results
The first mistake is starting with too many task types. Teams often test an AI employee across content, research, outreach, account checking, and reporting in the same week. That feels efficient, but it destroys the signal.
A failed run may come from bad instructions, weak permissions, unstable account state, or the wrong execution surface. Proof comes first.
Another mistake is allowing shared execution state. A global browser variable, unclear tab context, or reused run memory can make one task contaminate the next. Multi-browser and SaaS-style execution need user isolation, browser isolation, and run isolation.
Without those boundaries, parallel work becomes hard to trust. Name the owner.
Teams also underrate review design. A result is not operationally complete until the reviewer can see what happened, why it happened, and what should happen next. Screenshots, logs, task states, and exception categories are not decoration.
They are the control plane for human judgment. Stop early.
Avoid these patterns:
- Launching AI workers before account ownership is mapped.
- Treating mobile execution as a browser-only problem.
- Letting the model bypass policy when a site behaves unexpectedly.
- Measuring only completed tasks, while ignoring retries and recovery labor.
Fit Boundaries for an AI Employee Platform
This platform category fits best when the work has repeated inputs, defined environments, and visible review outcomes. Strong examples include routine account checks, asset movement, content preparation handoffs, mobile workflow execution, and browser dashboard tasks with clear stop rules.
The fit gets weaker when the work requires open-ended negotiation, creative strategy, or high-risk decisions without human review. The platform may still support preparation. It should not silently make final choices that affect money, access, or customer trust. Check the lane.
Repeatable growth task, known account context, clear evidence, bounded exception handling.
Ambiguous decision, unclear owner, no proof requirement, or changing workflow every run.
Tasks that cross browser and mobile surfaces but have a short review checklist.
Work where failure impact is high and the stop rule is not written down.
This boundary protects the team from over-automation. It also protects the platform from being blamed for work that was never specified clearly.
Clear limits help.
Pilot Rollout, Measurement, and Recovery Checks
A useful pilot should run for a small number of accounts, a fixed task lane, and a known review owner. The goal is not maximum volume. The goal is to learn whether the execution chain is clear enough to scale. Use fewer variables.
Track four numbers from the first week: completed runs, stopped runs, human interventions, and unclear failures. The last number matters most. A stopped run with a precise reason is manageable.
An unclear failure means the platform cannot yet explain its own behavior. Record the reason.
Review the pilot using a short weekly loop:
- Pick three completed runs and confirm the evidence is enough
- Pick three stopped runs and classify the cause
- Remove one unsupported task variation
- Add one missing stop rule or proof rule
- Expand only after recovery notes become routine
MoiMobi's mobile automation and phone farm layers become more useful after this loop is clear. Capacity should follow control, not replace it.
The review loop should include one negative sample. Pick a run that looked complete but required extra human checking. Then ask which field was missing. Small checks matter.
The answer may be proof type, account owner, route choice, or stop rule. Fixing that field usually improves more future work than adding a longer instruction.
Another useful habit is to separate retry from repair. A retry runs the same task again because the environment changed. A repair changes the task, field, permission, or rule because the system design was weak.
Treating every failure as a retry hides the problems that need design work. Fix one rule.
Frequently Asked Questions
What is an AI employee platform?
It assigns bounded digital work to software workers while controlling context, permissions, execution, evidence, and review. The useful version is closer to operations infrastructure than a chat assistant.
Does every task need browser automation?
No. Some tasks only need planning, drafting, classification, or review support. Browser execution becomes necessary when the worker must act inside a live web account or dashboard.
When does mobile execution matter?
Mobile execution matters when the work depends on app state, mobile identity, device context, or actions that cannot be completed reliably from a desktop browser alone.
How should a team start?
Start with one repeatable task lane and one review owner. Define the account group, allowed actions, proof requirements, and stop conditions before adding volume.
What is the biggest operational risk?
The biggest risk is unclear state. If the platform cannot show which environment was used and what happened, a human cannot judge the result quickly.
Is this only for growth teams?
No. Growth teams are a common fit, but support, marketplace operations, content operations, and account maintenance teams can use the same execution model.
What should be measured first?
Measure completion quality, stopped-run reasons, recovery time, and reviewer confidence. Volume is less useful until those four signals are stable.
Conclusion
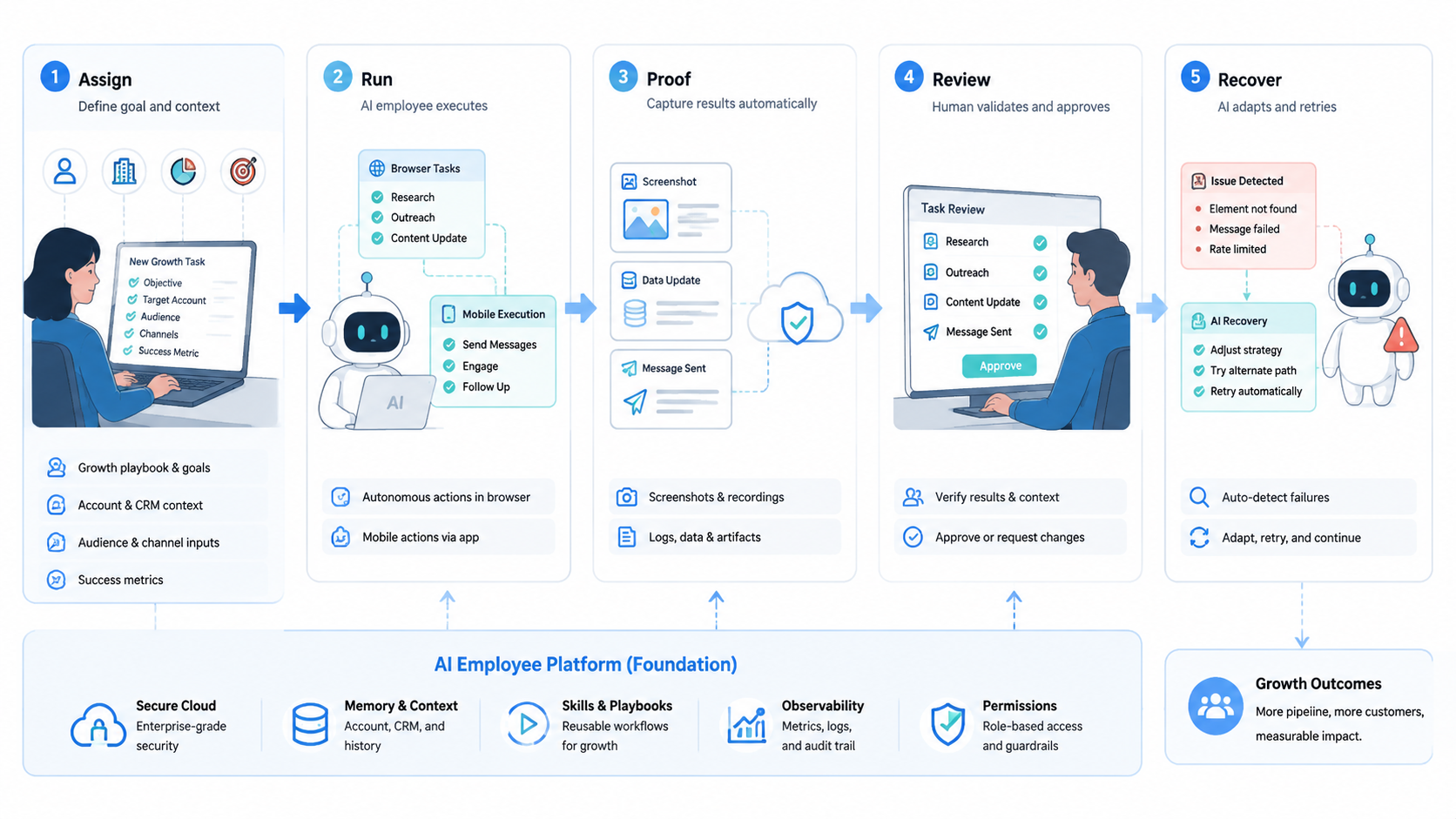
Real growth operations execution should be judged by control, not by claims about autonomy. The platform needs to bind each worker to the right environment, keep account and run state separate, enforce action boundaries, and leave evidence that a reviewer can trust.
The practical next step is to choose one task lane and write its execution contract. Name the account scope, browser or mobile surface, allowed actions, proof record, stop rule, and recovery owner. If that contract is hard to write, the team has found the real work to finish before scaling. Context wins.



